Optim Algo
Miscellaneous Optimization Algorithms I have learned about.
PapersWithCode
网站地址:https://paperswithcode.com/ 详细推文:(如何复现大佬论文的代码?)https://mp.weixin.qq.com/s/ydmwgHoQeSnfJXA1aEihUQ 其他科研必备小网站可以在:[公众号]左下角[R语言]专栏的[科研技巧]中找到。
dynamic routing
Developed for analyzing graphic input with different scale. (particularly in semantic segmentation)
Pic Source: DyRout-CSDN
capsule network
A new type of neuron processing vectors instead of scalars.
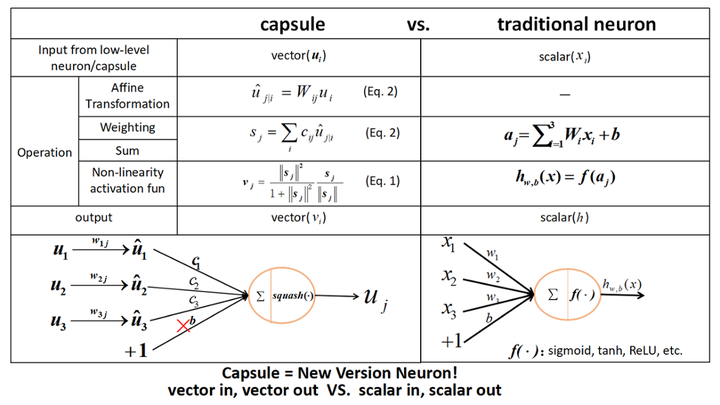 Pic Cited from DiscussionOnHinton’sWork,Zhihu
Pic Cited from DiscussionOnHinton’sWork,Zhihu
A very primary NN
基于neurolab的代码实现:{hopfield神经网络-知乎}
偏向理论和书本的细致讲解:{《人工神经网络》第四章-博客园}
这似乎是一中非常原始的神经网络,每个神经元只有2值决定输出与否,同时输入信息将被赋予weight & bias.
SMBO
Note: This post only mentioned the code operation of SMBO. It is dangerous to use the auto-tunner without thorough understanding on the math theories behind. Therefore, the post requires more explanation on math, especially on Objective Function and Acqusition Function (Expected Function)
- An example code in github Link
TPE, Tree Parzen Estimator, is a type of surrogate function for Squential Model Based Optimization. Squential Model Based Optimization with Tree Parzen Estimator. TPE is a tool, SMBO is a type of method.
If we use Bayesian theory to construct a surrgate function, then the method can be defined as Bayesian Model Based Optimization.
In Hyperopt, we just need to define the distribution to searach and objective function.
- Psedo code explanation of TPE
Link-Zhihu
The pesudo-code:
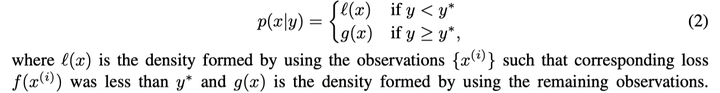
In summary, the TPE updates the distribution to seach on basis of the previous loss.
-
However, by the name TPE, we can tell that:
- ‘tree’ indicate the structure of the optimizor is tree;
- ‘estimator’ defines its work as estimating
- and what about ‘Parzen’?
-
Parzen Window
Parzen should be the name of an greek mathmatian. Another well-known probability axiom of him is Parzen Window, which is a method to ‘guess’ the global probility distribution from the probability of samples within the range.
Intuitively, Parzen window is related to Monte Carlo method, which is also describe the global distribution by probability of mulitple trials.
Here is a PPT for it. Link-baidu_wenku_PPT
Levenberg-Marquardt & Guassian- Newtown & Steepest Gradient
From Math to Code
Matlab中的默认训练方式trainlm()的数学原理和代码解析(完)
Math works
We randomly pick one of the state during the training process , with step length h which is sufficiently small, the Taylor expansion of corresponding cost function is: