Wrapped Dataset 已包装数据集
0702更新补充说明
本页数据集为早期本人打包,参数较少,采用张凤祥K公式反算磨损量,不推荐使用。
但由于数据打包思路类似,特此保留作为数据包装结构理解的辅助资料。
打包了原先的628条数据和新增的2000余条数据
Wrapped 628 data from 5 section and 2000+ data from 1 section
See you in one month.
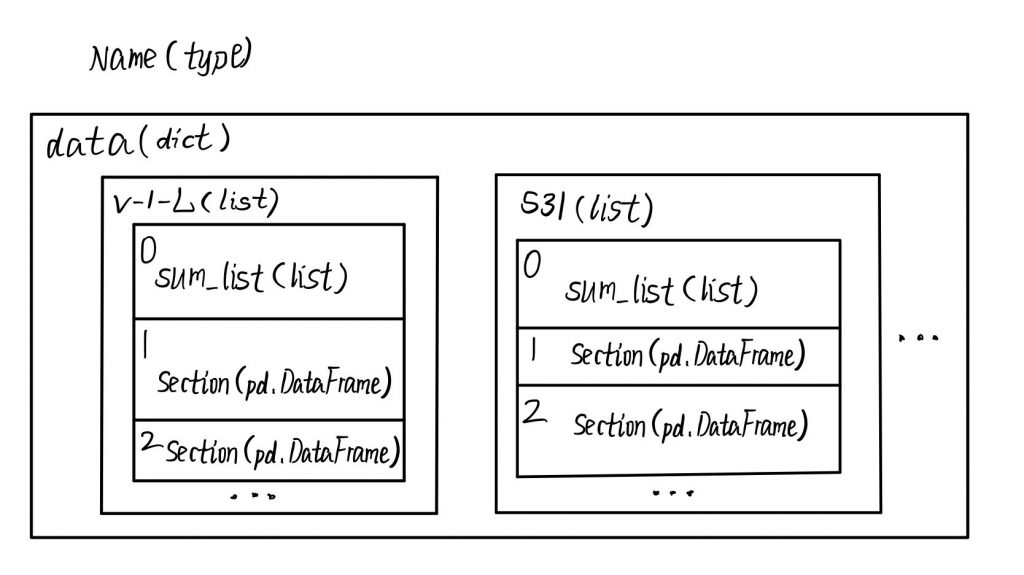
简介 Intro
dict用pickle进行了Deserialize的包装
data#.pkl的数据结构如下
应用示例 example codes
# 载入必要库
import pandas as pd
import pickle
# 存放路径,可修改
PATH = './Data/'
# pickle以'rb'模式,即二进制读取
# 存入data当中
with open(PATH+'data#.pkl', mode='rb') as f:
data = pickle.load(f)
#输出数据
print('data的类型是', type(data))
print('V-1-L的类型是', type(data['V-1-L']))
print('S31的类型是', type(data['S31']))
print('S31中list[0]的类型是', type(data['S31'][0]))
print('S31中各段磨损量是', data['S31'][0])
print('V-1-L区间第一段的数据类型是', type(data['V-1-L'][1]))
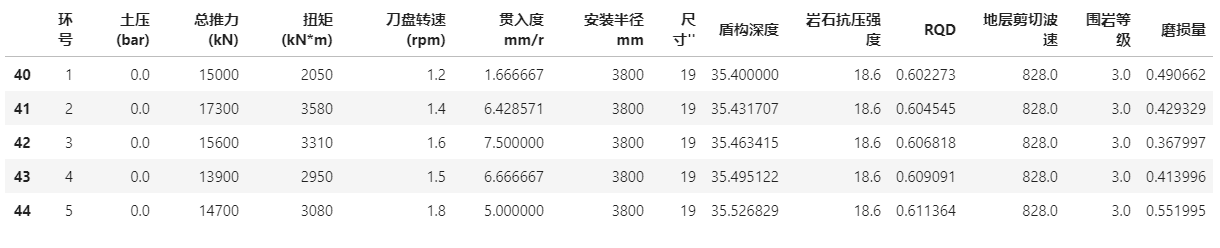
print('V-1-L区间第一段的数据的前5条是')
data['V-1-L'][1].head()输出结果
data的类型是 <class 'dict'> V-1-L的类型是 <class 'list'> S31的类型是 <class 'list'> S31中list[0]的类型是 <class 'list'> S31中各段磨损量是 [1.0, 1.0, 10.999999999999996, 4.000000000000001, 0.0, 4.0] V-1-L区间第一段的数据类型是 <class 'pandas.core.frame.DataFrame'> V-1-L区间第一段的数据的前5条是
Pages: 1 2